[7주차]수요일
오늘은 좀 피곤한 하루였다. 어제의 외출 때문인지, 프로젝트 때문에 잠이 좀 밀려서 인지 하루 종일 머리가 멍한 상태였다. 그런 상태 중에도 GPU를 놀리기 싫어 여러가지 변수를 바꿔가며 train.py를 계속 돌리려고 했던 것 같다.(큰 성과는 없었지만) 그 과정에서 어떤 걸 깨달았고 내일 추가적으로 어떤 것을 해볼지에 대해 적어보려 한다.
먼저 어제 자기 전에 learning scheduler를 적용한 model을 돌리고 잤었다. 아침에 일어나 학습 결과를 확인해 보니 같은 epoch 대비 확실히 빠르게 학습이 이루어 진 것을 확인할 수 있었다.
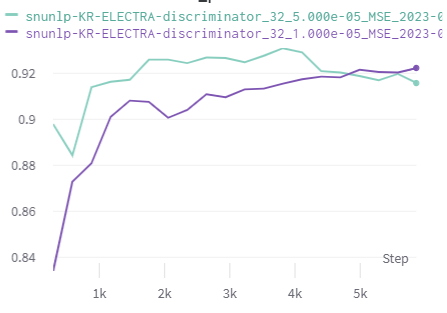
이를 통해 여러 모델에 scheduler를 적용해서 돌려 보았는데 대부분 비슷한 결과를 보였다. 위의 그래프를 보면 더 많은 epoch을 진행했을 때 성능이 조금 떨어지는 것을 확인할 수 있었는데 이는 overfitting 때문이라 판단하였다.
이것 말고도 오늘은 여러 모델에 대해서 실험을 해보려고 했다. 저번에 실험을 진행 했었던 monologg-koelectra-base-v3-discriminator 모델도 이용해보고 loss도 바꿔가며 어떤 부분이 가장 최적일지 찾아보려 했다. 하지만 실험을 하면서 계속 왜? 라는 의문이 들었다. 어떤 이유로 성능이 좋아지고 어떤 이유로 pearson 계수가 높아지는지 원인을 정확히 몰랐기 때문이다. 단순히 여러가지의 실험을 하면서 가장 좋은 성능의 모델을 찾기엔 너무 많은 시간이 걸릴 것 같다 생각되어서 어떤 확실한 가설을 통해 실험을 진행하고 싶은데 아직은 지식이 부족한 것 같다. 그래서 지금은 당장 내가 할 수 있는 data augumentation, loss, scheduler, k-fold, ensemble 등 의 방법을 이용해 봐야 할 것 같다.
자기 전 예전에 data augumentation을 했던 총 19000개의 데이터를 k-fold 이용한 모델을 돌려두고 자야겠다. 기존의 거의 2배의 데이터인 만큼 좋은 성능을 기대해보고 있다. 내일은 프로젝트의 마지막 날이기에 기존에 만들었던 여러 ckpt들을 모아 앙상블을 진행할 것 같다. 내일의 결과가 기대된다!